Guardrails - Quick Start
Setup Prompt Injection Detection, PII Masking on LiteLLM Proxy (AI Gateway)
1. Define guardrails on your LiteLLM config.yaml
Set your guardrails under the guardrails section
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: general-guard
litellm_params:
guardrail: aim
mode: [pre_call, post_call]
api_key: os.environ/AIM_API_KEY
api_base: os.environ/AIM_API_BASE
default_on: true # Optional
- guardrail_name: "aporia-pre-guard"
litellm_params:
guardrail: aporia # supported values: "aporia", "lakera"
mode: "during_call"
api_key: os.environ/APORIA_API_KEY_1
api_base: os.environ/APORIA_API_BASE_1
- guardrail_name: "aporia-post-guard"
litellm_params:
guardrail: aporia # supported values: "aporia", "lakera"
mode: "post_call"
api_key: os.environ/APORIA_API_KEY_2
api_base: os.environ/APORIA_API_BASE_2
guardrail_info: # Optional field, info is returned on GET /guardrails/list
# you can enter any fields under info for consumers of your guardrail
params:
- name: "toxicity_score"
type: "float"
description: "Score between 0-1 indicating content toxicity level"
- name: "pii_detection"
type: "boolean"
Supported values for mode (Event Hooks)
pre_callRun before LLM call, on inputpost_callRun after LLM call, on input & outputduring_callRun during LLM call, on input Same aspre_callbut runs in parallel as LLM call. Response not returned until guardrail check completes- A list of the above values to run multiple modes, e.g.
mode: [pre_call, post_call]
2. Start LiteLLM Gateway
litellm --config config.yaml --detailed_debug
3. Test request
Langchain, OpenAI SDK Usage Examples
- Unsuccessful call
- Successful Call
Expect this to fail since since ishaan@berri.ai in the request is PII
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi my email is ishaan@berri.ai"}
],
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
Expected response on failure
{
"error": {
"message": {
"error": "Violated guardrail policy",
"aporia_ai_response": {
"action": "block",
"revised_prompt": null,
"revised_response": "Aporia detected and blocked PII",
"explain_log": null
}
},
"type": "None",
"param": "None",
"code": "400"
}
}
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi what is the weather"}
],
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
Default On Guardrails
Set default_on: true in your guardrail config to run the guardrail on every request. This is useful if you want to run a guardrail on every request without the user having to specify it.
Note: These will run even if user specifies a different guardrail or empty guardrails array.
guardrails:
- guardrail_name: "aporia-pre-guard"
litellm_params:
guardrail: aporia
mode: "pre_call"
default_on: true
Test Request
In this request, the guardrail aporia-pre-guard will run on every request because default_on: true is set.
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi my email is ishaan@berri.ai"}
]
}'
Expected response
Your response headers will include x-litellm-applied-guardrails with the guardrail applied
x-litellm-applied-guardrails: aporia-pre-guard
Using Guardrails Client Side
Test yourself (OSS)
Pass guardrails to your request body to test it
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi my email is ishaan@berri.ai"}
],
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
Expose to your users (Enterprise)
Follow this simple workflow to implement and tune guardrails:
1. ✨ View Available Guardrails
✨ This is an Enterprise only feature Get a free trial
First, check what guardrails are available and their parameters:
Call /guardrails/list to view available guardrails and the guardrail info (supported parameters, description, etc)
curl -X GET 'http://0.0.0.0:4000/guardrails/list'
Expected response
{
"guardrails": [
{
"guardrail_name": "aporia-post-guard",
"guardrail_info": {
"params": [
{
"name": "toxicity_score",
"type": "float",
"description": "Score between 0-1 indicating content toxicity level"
},
{
"name": "pii_detection",
"type": "boolean"
}
]
}
}
]
}
This config will return the /guardrails/list response above. The guardrail_info field is optional and you can add any fields under info for consumers of your guardrail
- guardrail_name: "aporia-post-guard"
litellm_params:
guardrail: aporia # supported values: "aporia", "lakera"
mode: "post_call"
api_key: os.environ/APORIA_API_KEY_2
api_base: os.environ/APORIA_API_BASE_2
guardrail_info: # Optional field, info is returned on GET /guardrails/list
# you can enter any fields under info for consumers of your guardrail
params:
- name: "toxicity_score"
type: "float"
description: "Score between 0-1 indicating content toxicity level"
- name: "pii_detection"
type: "boolean"
2. Apply Guardrails
Add selected guardrails to your chat completion request:
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "your message"}],
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
3. Test with Mock LLM completions
Send mock_response to test guardrails without making an LLM call. More info on mock_response here
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi my email is ishaan@berri.ai"}
],
"mock_response": "This is a mock response",
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
4. ✨ Pass Dynamic Parameters to Guardrail
✨ This is an Enterprise only feature Get a free trial
Use this to pass additional parameters to the guardrail API call. e.g. things like success threshold. See guardrails spec for more details
- OpenAI Python v1.0.0+
- Curl Request
Set guardrails={"aporia-pre-guard": {"extra_body": {"success_threshold": 0.9}}} to pass additional parameters to the guardrail
In this example success_threshold=0.9 is passed to the aporia-pre-guard guardrail request body
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"guardrails": [
"aporia-pre-guard": {
"extra_body": {
"success_threshold": 0.9
}
}
]
}
)
print(response)
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"guardrails": [
"aporia-pre-guard": {
"extra_body": {
"success_threshold": 0.9
}
}
]
}'
Proxy Admin Controls
✨ Monitoring Guardrails
Monitor which guardrails were executed and whether they passed or failed. e.g. guardrail going rogue and failing requests we don't intend to fail
✨ This is an Enterprise only feature Get a free trial
Setup
- Connect LiteLLM to a supported logging provider
- Make a request with a
guardrailsparameter - Check your logging provider for the guardrail trace
Traced Guardrail Success
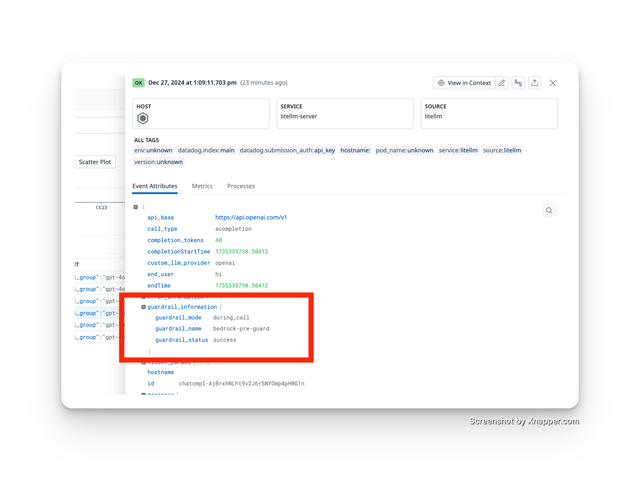
Traced Guardrail Failure
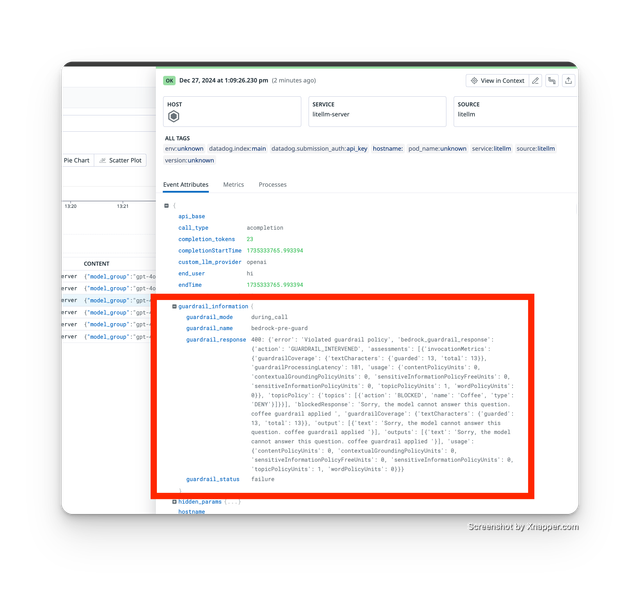
✨ Control Guardrails per API Key
✨ This is an Enterprise only feature Get a free trial
Use this to control what guardrails run per API Key. In this tutorial we only want the following guardrails to run for 1 API Key
guardrails: ["aporia-pre-guard", "aporia-post-guard"]
Step 1 Create Key with guardrail settings
- /key/generate
- /key/update
curl -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}
}'
curl --location 'http://0.0.0.0:4000/key/update' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"key": "sk-jNm1Zar7XfNdZXp49Z1kSQ",
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}
}'
Step 2 Test it with new key
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-jNm1Zar7XfNdZXp49Z1kSQ' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "my email is ishaan@berri.ai"
}
]
}'
✨ Tag-based Guardrail Modes
✨ This is an Enterprise only feature Get a free trial
Run guardrails based on the user-agent header. This is useful for running pre-call checks on OpenWebUI but only masking in logs for Claude CLI.
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "guardrails_ai-guard"
litellm_params:
guardrail: guardrails_ai
guard_name: "pii_detect" # 👈 Guardrail AI guard name
mode:
tags:
"User-Agent: claude-cli": "logging_only" # Claude CLI - only mask in logs
default: "pre_call" # Default mode when no tags match
api_base: os.environ/GUARDRAILS_AI_API_BASE # 👈 Guardrails AI API Base. Defaults to "http://0.0.0.0:8000"
default_on: true # run on every request
✨ Model-level Guardrails
✨ This is an Enterprise only feature Get a free trial
This is great for cases when you have an on-prem and hosted model, and just want to run prevent sending PII to the hosted model.
model_list:
- model_name: claude-sonnet-4
litellm_params:
model: anthropic/claude-sonnet-4-20250514
api_key: os.environ/ANTHROPIC_API_KEY
api_base: https://api.anthropic.com/v1
guardrails: ["azure-text-moderation"]
- model_name: openai-gpt-4o
litellm_params:
model: openai/gpt-4o
guardrails:
- guardrail_name: "presidio-pii"
litellm_params:
guardrail: presidio # supported values: "aporia", "bedrock", "lakera", "presidio"
mode: "pre_call"
presidio_language: "en" # optional: set default language for PII analysis
pii_entities_config:
PERSON: "BLOCK" # Will mask credit card numbers
- guardrail_name: azure-text-moderation
litellm_params:
guardrail: azure/text_moderations
mode: "post_call"
api_key: os.environ/AZURE_GUARDRAIL_API_KEY
api_base: os.environ/AZURE_GUARDRAIL_API_BASE
✨ Disable team from turning on/off guardrails
✨ This is an Enterprise only feature Get a free trial
1. Disable team from modifying guardrails
curl -X POST 'http://0.0.0.0:4000/team/update' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-D '{
"team_id": "4198d93c-d375-4c83-8d5a-71e7c5473e50",
"metadata": {"guardrails": {"modify_guardrails": false}}
}'
2. Try to disable guardrails for a call
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer $LITELLM_VIRTUAL_KEY' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Think of 10 random colors."
}
],
"metadata": {"guardrails": {"hide_secrets": false}}
}'
3. Get 403 Error
{
"error": {
"message": {
"error": "Your team does not have permission to modify guardrails."
},
"type": "auth_error",
"param": "None",
"code": 403
}
}
Expect to NOT see +1 412-612-9992 in your server logs on your callback.
The pii_masking guardrail ran on this request because api key=sk-jNm1Zar7XfNdZXp49Z1kSQ has "permissions": {"pii_masking": true}
Specification
guardrails Configuration on YAML
guardrails:
- guardrail_name: string # Required: Name of the guardrail
litellm_params: # Required: Configuration parameters
guardrail: string # Required: One of "aporia", "bedrock", "guardrails_ai", "lakera", "presidio", "hide-secrets"
mode: Union[string, List[string], Mode] # Required: One or more of "pre_call", "post_call", "during_call", "logging_only"
api_key: string # Required: API key for the guardrail service
api_base: string # Optional: Base URL for the guardrail service
default_on: boolean # Optional: Default False. When set to True, will run on every request, does not need client to specify guardrail in request
guardrail_info: # Optional[Dict]: Additional information about the guardrail
Mode Specification
from litellm.types.guardrails import Mode
mode = Mode(
tags={"User-Agent: claude-cli": "logging_only"},
default="logging_only"
)
guardrails Request Parameter
The guardrails parameter can be passed to any LiteLLM Proxy endpoint (/chat/completions, /completions, /embeddings).
Format Options
- Simple List Format:
"guardrails": [
"aporia-pre-guard",
"aporia-post-guard"
]
- Advanced Dictionary Format:
In this format the dictionary key is guardrail_name you want to run
"guardrails": {
"aporia-pre-guard": {
"extra_body": {
"success_threshold": 0.9,
"other_param": "value"
}
}
}
Type Definition
guardrails: Union[
List[str], # Simple list of guardrail names
Dict[str, DynamicGuardrailParams] # Advanced configuration
]
class DynamicGuardrailParams:
extra_body: Dict[str, Any] # Additional parameters for the guardrail